 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiameseNorm: Breaking the Barrier to Reconciling Pre/Post-Norm
Feb 08, 2026Modern Transformers predominantly adopt the Pre-Norm paradigm for its optimization stability, foregoing the superior potential of the unstable Post-Norm architecture. Prior attempts to combine their strengths typically lead to a stability-performance trade-off. We attribute this phenomenon to a structural incompatibility within a single-stream design: Any application of the Post-Norm operation inevitably obstructs the clean identity gradient preserved by Pre-Norm. To fundamentally reconcile these paradigms, we propose SiameseNorm, a two-stream architecture that couples Pre-Norm-like and Post-Norm-like streams with shared parameters. This design decouples the optimization dynamics of the two streams, retaining the distinct characteristics of both Pre-Norm and Post-Norm by enabling all residual blocks to receive combined gradients inherited from both paradigms, where one stream secures stability while the other enhances expressivity. Extensive pre-training experiments on 1.3B-parameter models demonstrate that SiameseNorm exhibits exceptional optimization robustness and consistently outperforms strong baselines. Code is available at https://github.com/Qwen-Applications/SiameseNorm.
A Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training
Jan 30, 2026We investigate the functional role of emergent outliers in large language models, specifically attention sinks (a few tokens that consistently receive large attention logits) and residual sinks (a few fixed dimensions with persistently large activations across most tokens). We hypothesize that these outliers, in conjunction with the corresponding normalizations (\textit{e.g.}, softmax attention and RMSNorm), effectively rescale other non-outlier components. We term this phenomenon \textit{outlier-driven rescaling} and validate this hypothesis across different model architectures and training token counts. This view unifies the origin and mitigation of both sink types. Our main conclusions and observations include: (1) Outliers function jointly with normalization: removing normalization eliminates the corresponding outliers but degrades training stability and performance; directly clipping outliers while retaining normalization leads to degradation, indicating that outlier-driven rescaling contributes to training stability. (2) Outliers serve more as rescale factors rather than contributors, as the final contributions of attention and residual sinks are significantly smaller than those of non-outliers. (3) Outliers can be absorbed into learnable parameters or mitigated via explicit gated rescaling, leading to improved training performance (average gain of 2 points) and enhanced quantization robustness (1.2 points degradation under W4A4 quantization).
SageAttention2++: A More Efficient Implementation of SageAttention2
May 28, 2025
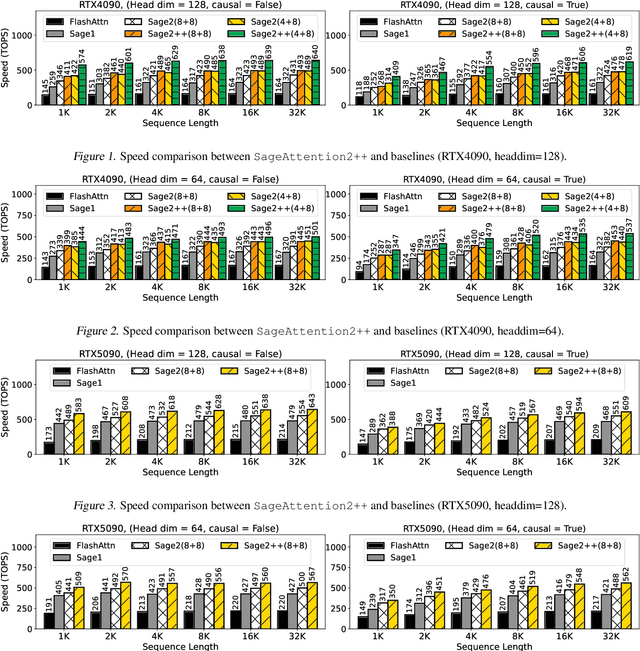
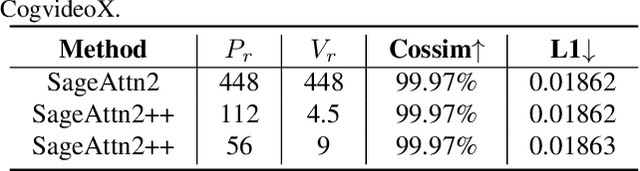
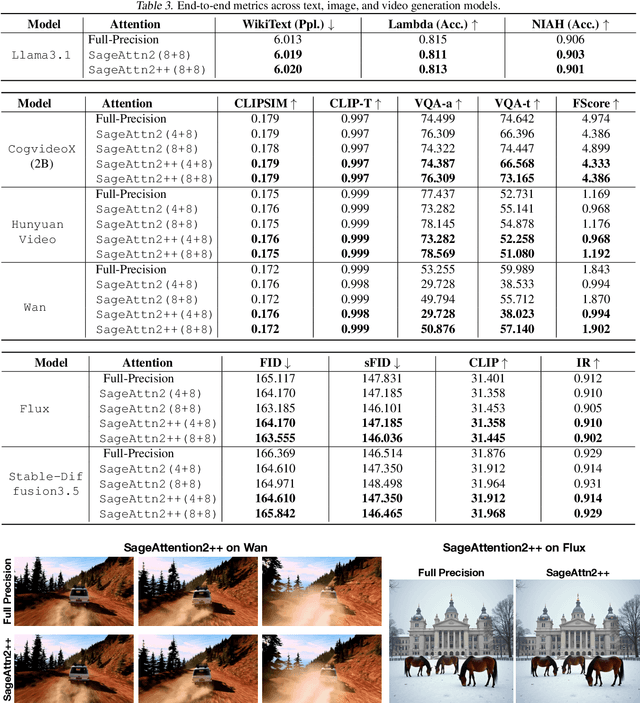
The efficiency of attention is critical because its time complexity grows quadratically with sequence length. SageAttention2 addresses this by utilizing quantization to accelerate matrix multiplications (Matmul) in attention. To further accelerate SageAttention2, we propose to utilize the faster instruction of FP8 Matmul accumulated in FP16. The instruction is 2x faster than the FP8 Matmul used in SageAttention2. Our experiments show that SageAttention2++ achieves a 3.9x speedup over FlashAttention while maintaining the same attention accuracy as SageAttention2. This means SageAttention2++ effectively accelerates various models, including those for language, image, and video generation, with negligible end-to-end metrics loss. The code will be available at https://github.com/thu-ml/SageAttention.
Faster Video Diffusion with Trainable Sparse Attention
May 19, 2025



Scaling video diffusion transformers (DiTs) is limited by their quadratic 3D attention, even though most of the attention mass concentrates on a small subset of positions. We turn this observation into VSA, a trainable, hardware-efficient sparse attention that replaces full attention at \emph{both} training and inference. In VSA, a lightweight coarse stage pools tokens into tiles and identifies high-weight \emph{critical tokens}; a fine stage computes token-level attention only inside those tiles subjecting to block computing layout to ensure hard efficiency. This leads to a single differentiable kernel that trains end-to-end, requires no post-hoc profiling, and sustains 85\% of FlashAttention3 MFU. We perform a large sweep of ablation studies and scaling-law experiments by pretraining DiTs from 60M to 1.4B parameters. VSA reaches a Pareto point that cuts training FLOPS by 2.53$\times$ with no drop in diffusion loss. Retrofitting the open-source Wan-2.1 model speeds up attention time by 6$\times$ and lowers end-to-end generation time from 31s to 18s with comparable quality. These results establish trainable sparse attention as a practical alternative to full attention and a key enabler for further scaling of video diffusion models.
SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
May 16, 2025The efficiency of attention is important due to its quadratic time complexity. We enhance the efficiency of attention through two key contributions: First, we leverage the new FP4 Tensor Cores in Blackwell GPUs to accelerate attention computation. Our implementation achieves 1038 TOPS on RTX5090, which is a 5x speedup over the fastest FlashAttention on RTX5090. Experiments show that our FP4 attention can accelerate inference of various models in a plug-and-play way. Second, we pioneer low-bit attention to training tasks. Existing low-bit attention works like FlashAttention3 and SageAttention focus only on inference. However, the efficiency of training large models is also important. To explore whether low-bit attention can be effectively applied to training tasks, we design an accurate and efficient 8-bit attention for both forward and backward propagation. Experiments indicate that 8-bit attention achieves lossless performance in fine-tuning tasks but exhibits slower convergence in pretraining tasks. The code will be available at https://github.com/thu-ml/SageAttention.
XAttention: Block Sparse Attention with Antidiagonal Scoring
Mar 20, 2025



Long-Context Transformer Models (LCTMs) are vital for real-world applications but suffer high computational costs due to attention's quadratic complexity. Block-sparse attention mitigates this by focusing computation on critical regions, yet existing methods struggle with balancing accuracy and efficiency due to costly block importance measurements. In this paper, we introduce XAttention, a plug-and-play framework that dramatically accelerates long-context inference in Transformers models using sparse attention. XAttention's key innovation is the insight that the sum of antidiagonal values (i.e., from the lower-left to upper-right) in the attention matrix provides a powerful proxy for block importance. This allows for precise identification and pruning of non-essential blocks, resulting in high sparsity and dramatically accelerated inference. Across comprehensive evaluations on demanding long-context benchmarks-including RULER and LongBench for language, VideoMME for video understanding, and VBench for video generation. XAttention achieves accuracy comparable to full attention while delivering substantial computational gains. We demonstrate up to 13.5x acceleration in attention computation. These results underscore XAttention's ability to unlock the practical potential of block sparse attention, paving the way for scalable and efficient deployment of LCTMs in real-world applications. Code is available at https://github.com/mit-han-lab/x-attention.
SpargeAttn: Accurate Sparse Attention Accelerating Any Model Inference
Feb 25, 2025An efficient attention implementation is essential for large models due to its quadratic time complexity. Fortunately, attention commonly exhibits sparsity, i.e., many values in the attention map are near zero, allowing for the omission of corresponding computations. Many studies have utilized the sparse pattern to accelerate attention. However, most existing works focus on optimizing attention within specific models by exploiting certain sparse patterns of the attention map. A universal sparse attention that guarantees both the speedup and end-to-end performance of diverse models remains elusive. In this paper, we propose SpargeAttn, a universal sparse and quantized attention for any model. Our method uses a two-stage online filter: in the first stage, we rapidly and accurately predict the attention map, enabling the skip of some matrix multiplications in attention. In the second stage, we design an online softmax-aware filter that incurs no extra overhead and further skips some matrix multiplications. Experiments show that our method significantly accelerates diverse models, including language, image, and video generation, without sacrificing end-to-end metrics. The codes are available at https://github.com/thu-ml/SpargeAttn.
SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug-and-play Inference Acceleration
Nov 17, 2024



Although quantization for linear layers has been widely used, its application to accelerate the attention process remains limited. SageAttention utilizes 8-bit matrix multiplication, 16-bit matrix multiplication with 16-bit accumulator, and precision-enhancing methods, implementing an accurate and 2x speedup kernel compared to FlashAttention2. To further enhance the efficiency of attention computation while maintaining precision, we propose SageAttention2, which utilizes significantly faster 4-bit matrix multiplication (Matmul) alongside additional precision-enhancing techniques. First, we propose to quantize matrixes $(Q, K)$ to INT4 in a warp-level granularity and quantize matrixes $(\widetilde P, V)$ to FP8. Second, we propose a method to smooth $Q$ and $V$, enhancing the accuracy of attention with INT4 $QK$ and FP8 $PV$. Third, we analyze the quantization accuracy across timesteps and layers, then propose an adaptive quantization method to ensure the end-to-end metrics over various models. The operations per second (OPS) of SageAttention2 surpass FlashAttention2 and xformers by about 3x and 5x on RTX4090, respectively. Comprehensive experiments confirm that our approach incurs negligible end-to-end metrics loss across diverse models, including those for large language processing, image generation, and video generation. The codes are available at https://github.com/thu-ml/SageAttention.
MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression
Jun 21, 2024



Sparse attention can effectively mitigate the significant memory and throughput demands of Large Language Models (LLMs) in long contexts. Existing methods typically employ a uniform sparse attention mask, applying the same sparse pattern across different attention heads and input lengths. However, this uniform approach fails to capture the diverse attention patterns inherent in LLMs, ignoring their distinct accuracy-latency trade-offs. To address this challenge, we propose the Mixture of Attention (MoA), which automatically tailors distinct sparse attention configurations to different heads and layers. MoA constructs and navigates a search space of various attention patterns and their scaling rules relative to input sequence lengths. It profiles the model, evaluates potential configurations, and pinpoints the optimal sparse attention compression plan. MoA adapts to varying input sizes, revealing that some attention heads expand their focus to accommodate longer sequences, while other heads consistently concentrate on fixed-length local contexts. Experiments show that MoA increases the effective context length by $3.9\times$ with the same average attention span, boosting retrieval accuracy by $1.5-7.1\times$ over the uniform-attention baseline across Vicuna-7B, Vicuna-13B, and Llama3-8B models. Moreover, MoA narrows the capability gaps between sparse and dense models, reducing the maximum relative performance drop from $9\%-36\%$ to within $5\%$ across two long-context understanding benchmarks. MoA achieves a $1.2-1.4\times$ GPU memory reduction and boosts decode throughput by $5.5-6.7 \times$ for 7B and 13B dense models on a single GPU, with minimal impact on performance.
FreeMotion: MoCap-Free Human Motion Synthesis with Multimodal Large Language Models
Jun 15, 2024Human motion synthesis is a fundamental task in computer animation. Despite recent progress in this field utilizing deep learning and motion capture data, existing methods are always limited to specific motion categories, environments, and styles. This poor generalizability can be partially attributed to the difficulty and expense of collecting large-scale and high-quality motion data. At the same time, foundation models trained with internet-scale image and text data have demonstrated surprising world knowledge and reasoning ability for various downstream tasks. Utilizing these foundation models may help with human motion synthesis, which some recent works have superficially explored. However, these methods didn't fully unveil the foundation models' potential for this task and only support several simple actions and environments. In this paper, we for the first time, without any motion data, explore open-set human motion synthesis using natural language instructions as user control signals based on MLLMs across any motion task and environment. Our framework can be split into two stages: 1) sequential keyframe generation by utilizing MLLMs as a keyframe designer and animator; 2) motion filling between keyframes through interpolation and motion tracking. Our method can achieve general human motion synthesis for many downstream tasks. The promising results demonstrate the worth of mocap-free human motion synthesis aided by MLLMs and pave the way for future research.